Case study · Research
Signal — catching drift before it becomes failure
An applied-research project on detecting anomalies in high-volume sensor telemetry — flagging the early statistical drift that precedes equipment failure. [placeholder summary — replace with your research]
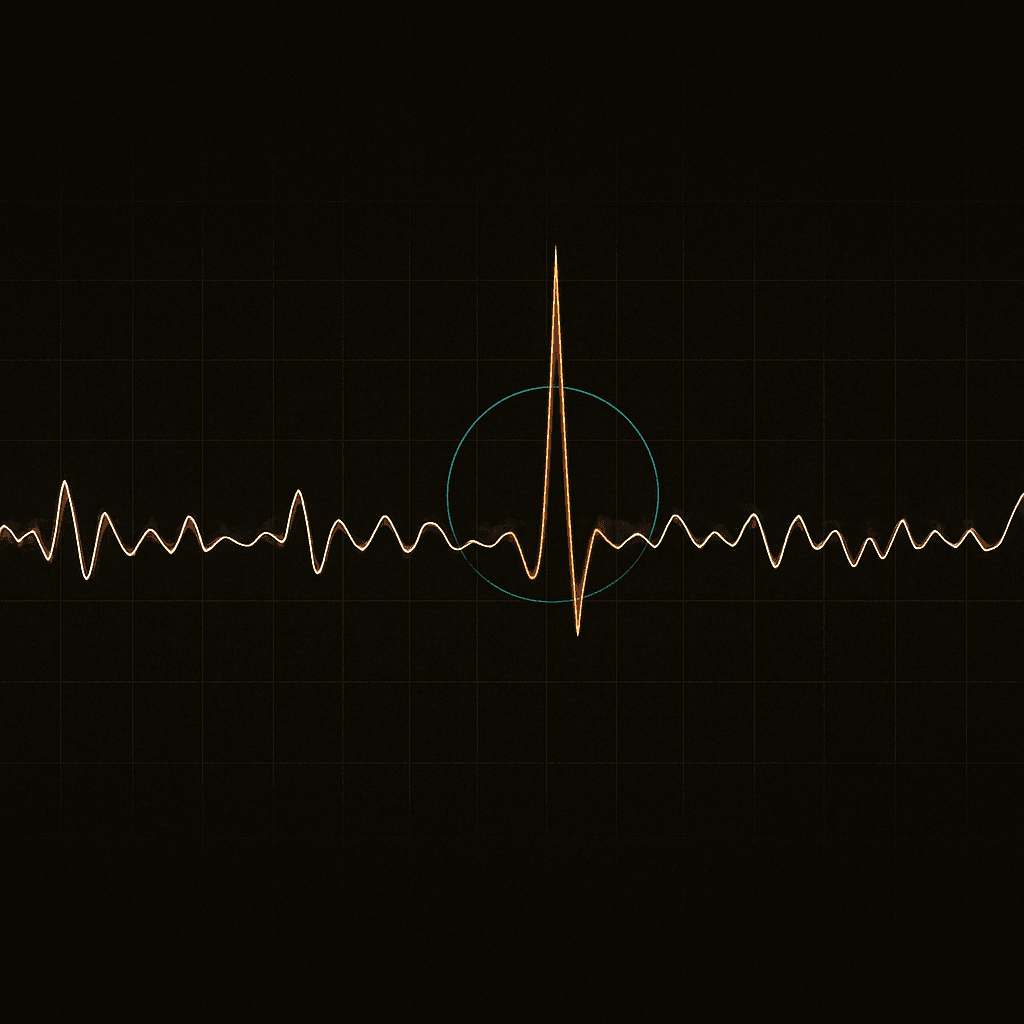
Fig. 01 — Drop in your hero figure or system diagram (21:9). [placeholder]
02 — The problem
By the time a threshold trips, the failure has already started
Classic monitoring waits for a metric to cross a fixed line. But in noisy, high-frequency telemetry the meaningful change is a slow shift in the shape of the distribution — long before any single reading looks alarming. The question: can we detect that drift early, cheaply, and without drowning operators in false alarms?
~50k readings/sec across thousands of sensors. [ph]
Alarms must stay actionable — low false-positive budget. [ph]
Detection has to run online, in near real time. [ph]
03 — Process
How the system came together
STEP 01 · Frame
Define drift in measurable terms
Settled on a windowed distributional distance as the target signal, so "drift" became something we could score and threshold. [placeholder]
STEP 02 · Build
A streaming feature + scoring pipeline
Rolling statistics computed online, fed into a lightweight detector that emits a calibrated drift score per sensor. [placeholder]
STEP 03 · Test
Backtest against labelled failures
Replayed historical incidents to measure lead time and false-alarm rate, then tuned the alert budget. [placeholder]
detector pipeline or backtest results
Fig. 02 — Replace with a pipeline diagram or results chart. [placeholder]
04 — Outcome
Earlier warnings, fewer false alarms
The detector caught the early phase of every labelled failure in the test set while cutting alert volume by roughly two-thirds — turning a noisy stream into a short, trustworthy queue an operator can actually work. A preprint and an open prototype came out of it. [placeholder]
Next project